Transformer-based-llm Attention
It starts with the question
If attention works so well at highlighting important inputs, why do we need all these recurrent things to start with?
A model where everything attends to everything else
Overall Structure
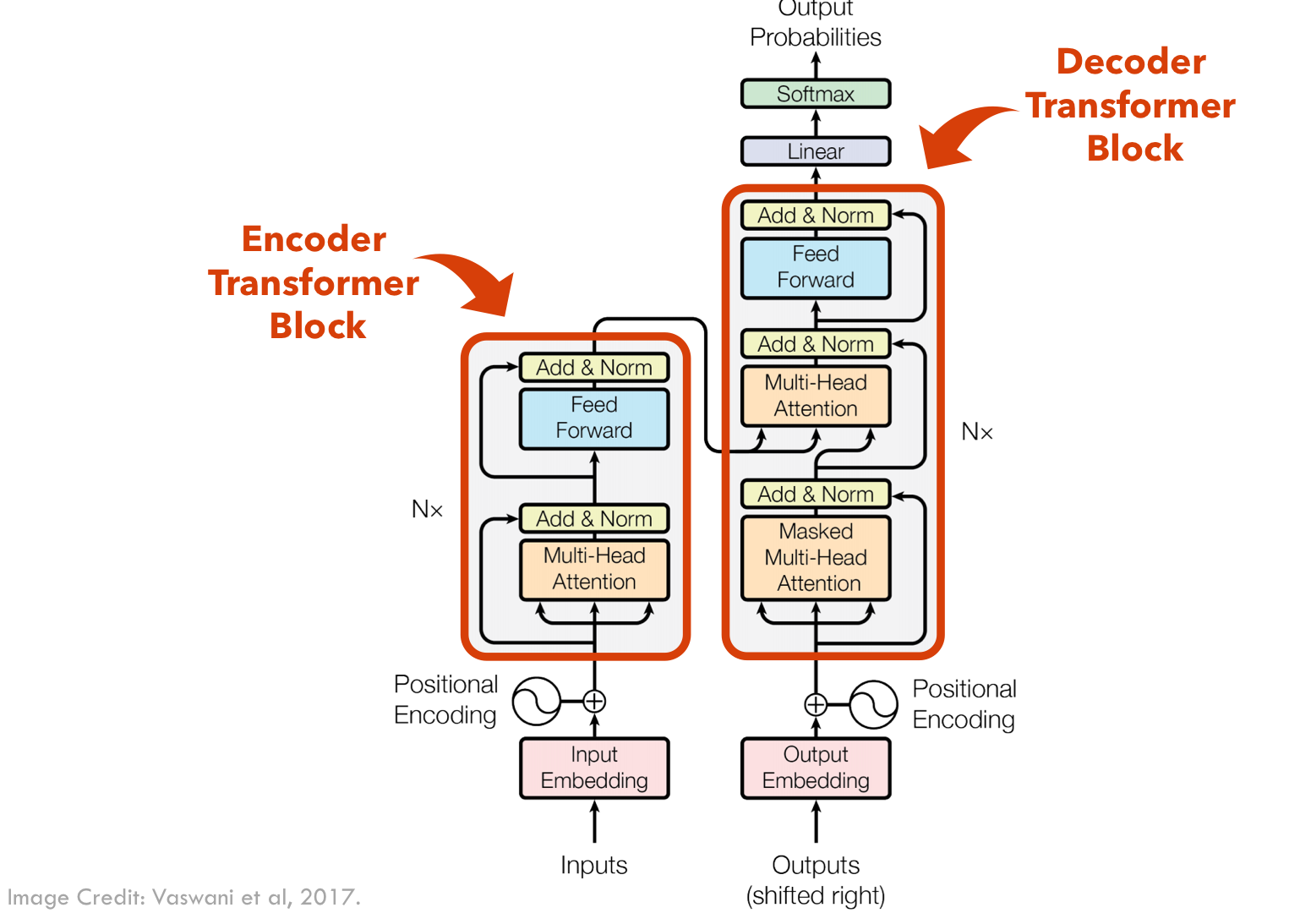
Multi-head attention
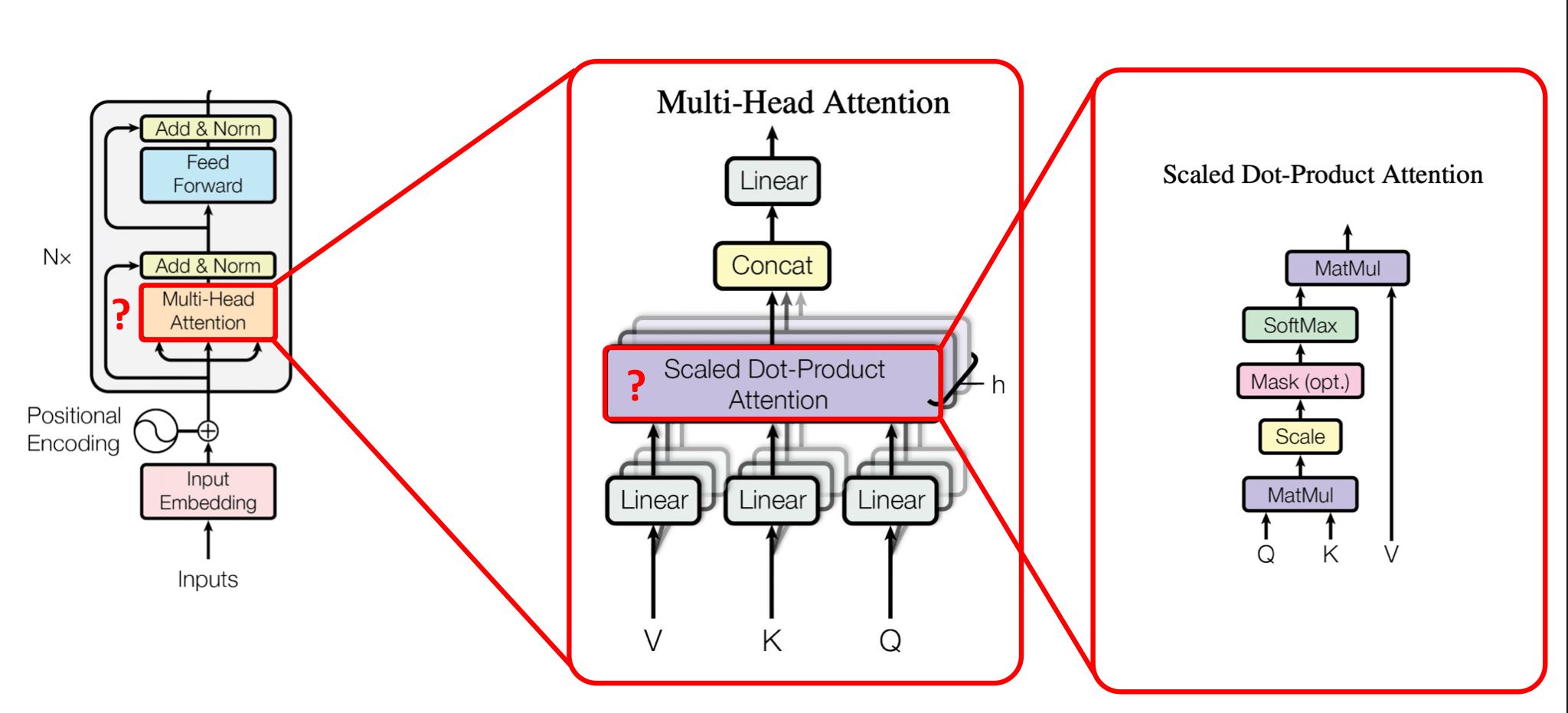
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
Motivation
Instead of performing a single attention function, we run multiple attention heads in parallel. This allows the model to capture different aspects of the relationships between tokens (e.g., syntax vs. semantics).
Formula Overview
Given:
- Input: Queries Q, Keys K, Values V
- Weight matrices: for each head
- Output projection:
For each head ( h ), we compute:
Q, K, V is
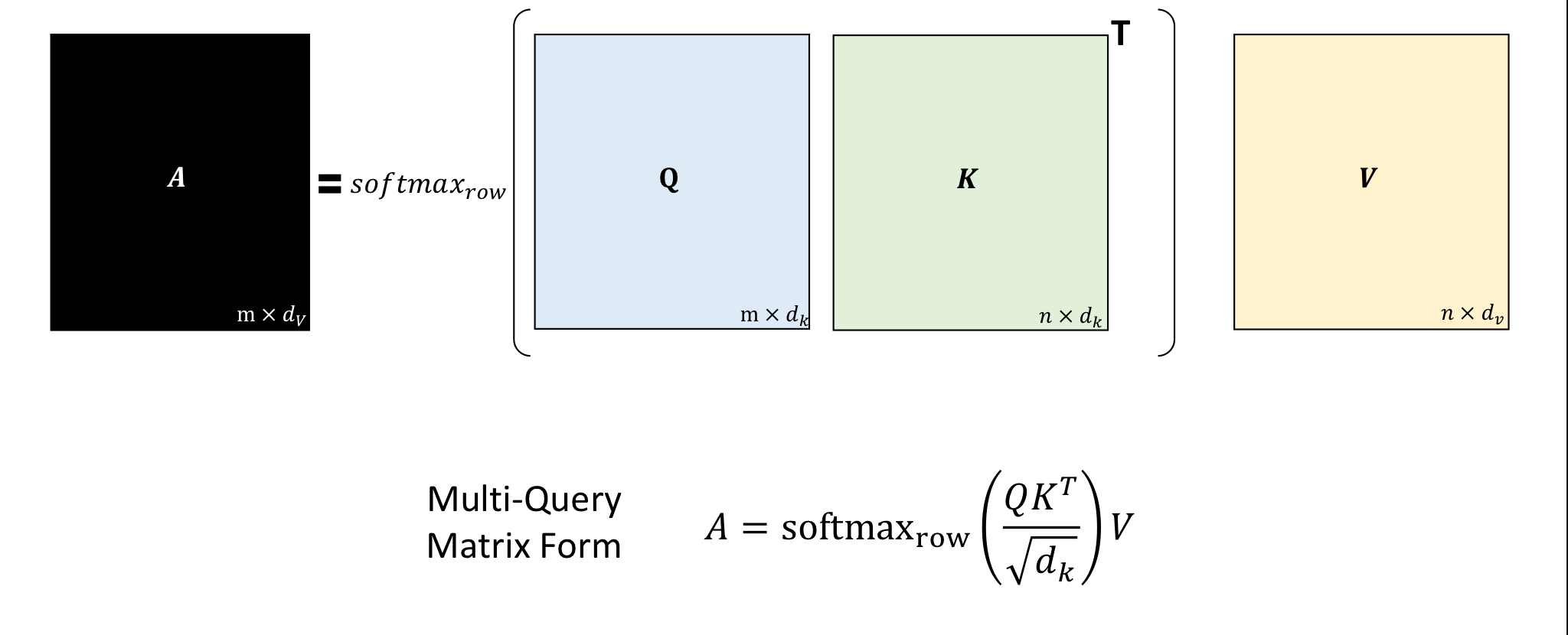
Perform scaled dot-product attention:
Divide by , so that we don’t have to hyperparam tune whenever we change dimension
Then concatenate all heads and project:
Step-by-Step Breakdown
-
Linear projections of Q, K, and V using learned weights ,,
-
Scaled dot-product attention is computed separately for each head
-
Concatenate all heads’ outputs
-
Final linear projection using
Matrix Dimensions
| Component | Shape |
|---|---|
| Q, K, V | (seq_len, d_model) |
| W^Q, W^K, W^V | (d_model, d_k or d_v) |
| Q^{(h)}, K^{(h)} | (seq_len, d_k) |
| Output per head | (seq_len, d_v) |
| Final output | (seq_len, H × d_v) → (seq_len, d_model) after W^O |
Why Multiple Heads?
-
Attend to different things (e.g., subject-verb agreement, word order, phrase-level context)
-
Learn different subspace representations
-
Aggregate richer and more diverse information
-
Shown empirically to improve performance over single-head attention
Each attention head performs:
Q, K, V → Scaled Dot-Product Attention →
Then:
→ Final Output
Layer Normalization
- Compute mean and std of activation:
- Subtract mean and divide by std
This way we can scale and shift, providing flexibility.
Why transformer architecture rather than RNN
- Everything is feedforward: Parallel training, Full leverage of GPU
- Every time step can attend to any others: No range limit of interaction, No more memory or vanishing gradient through time